Key to Simplicity: Squeezing the hassle out of encryption key recovery

Cryptography transforms the impossible task of safeguarding extensive data transmitted and stored across numerous systems and networks into the simpler task of securing a small singular key in one location. It is a magical thing. However, as services increasingly adopt end-to-end encryption for privacy features, this single small key has emerged as something with challenges and problems of its own.
One of the most notable challenges is ensuring that someone (but only that someone!) has continued access to the encryption keys protecting their data, regardless of whether they reinstall an app, lose their phone, or encounter any of the other myriad pitfalls of life.
Unfortunately, the default approach to these problems is often to place the burden directly onto the user by requiring them to manage a backup of their secret key. These keys are too long to memorize and are challenging for users to store securely. This complexity becomes especially evident when users need to input their key material on a new device, leading some to opt for less secure alternatives instead of navigating the secure platform.
Unlocking the key conundrum
Various solutions have been proposed to address this issue. In the web3/crypto space, seed phrases offer a slight simplification by representing a key as a series of words, but they still require users to manage lengthy and unmemorable strings. Passkeys prove more compelling by eliminating the need for users to remember key material, but introduce their own UX challenges when storing and transferring this material across devices, and their own security challenges when considering how they are backed up themselves.
The field of “password based encryption” aimed to solve this issue by transforming short user-memorable passwords into encryption keys through iterative hashing or the like, such that an encryption key can always be recovered from something that a user can remember. However, regardless of how a key derivation function is tuned, these systems have proven very vulnerable to attackers that employ dictionary or brute force attacks to make guesses until they too are able to recover the correct key.
Some of the most promising solutions to date leverage secure hardware, such as programmable Hardware Security Modules (HSMs). The innovation here is that secure hardware can be used to limit an attacker’s ability to make guesses, so that short user-memorable inputs can be transformed into encryption keys without the same risks of brute forcing or dictionary attacks that came with traditional password based encryption.
Indeed, companies like Apple and WhatsApp use programmable HSMs in this way to enable end-to-end backup of keys protecting some user data. Their interface typically involves logging into an account (using an Apple ID or phone number) and entering a 6-digit PIN. This PIN is indirectly used to protect a secret, and the HSM prevents an attacker (including the operator) from brute forcing. Signal’s Secure Value Recovery was an initial proof of concept for this type of system, but relies on a weaker version of secure hardware (Intel’s SGX) to provide a simplified PIN based user interface using a similar underlying mechanism.
However, while relying on hardware security reduces user burden, it assumes the inherent security of a specific set of hardware and firmware. The safety of your secrets becomes contingent on the security of the hardware used to recover them, which can lead to challenges in keeping up with evolving hardware vulnerabilities. Moreover, secure hardware is often performance-constrained, outdated, and costly, posing sustainability issues at scale.
Juicebox: Blending ease and security without the pulp
We have designed Juicebox to solve these problems. Like some of the most promising solutions to date, Juicebox allows a user to recover their secret material by remembering a short PIN, without having access to any previous devices – but also without placing trust in any single party or hardware manufacturer.
Additionally, Juicebox:
- Never gives any service access to a user’s secret material or PIN.
- Distributes trust across mutually distrusting services, eliminating the need to trust any singular server operator or hardware vendor.
- Prevents brute-force attacks by limiting attempts.
- Allows auditing of secret access attempts.
We’re able to achieve these goals without the security trade-offs seen in HSMs alone by combining existing, proven distributed cryptography techniques to minimize the risks traditionally associated with them. All while keeping user burden low by allowing recovery through memorable low-entropy PINs, and maintaining similar security to solutions utilizing high-entropy keys.
Learning to share
The most straightforward version of standard HSM based key recovery looks like this:
- The client establishes a secure connection with the process running in the HSM.
- The client transmits a key to the HSM, along with a PIN the user selects.
- The HSM securely stores the key, the PIN, and a guess counter associated with that user.
- In the future, the HSM will return the key to the client if it can present the correct PIN.
- The HSM uses the guess counter to limit the total number of possible PIN attempts a client gets.
Obviously, if the HSM is compromised, all user data is compromised along with it. For Juicebox, our initial challenge was to sever this link between the security of a user secret and the security of the single server where it is stored.
The first step is to allow for distributing trust beyond a single organization or HSM vendor. Juicebox employs a strategy of distributing secrets across n independent services, each implementing the Juicebox Protocol, and retrieving them from a threshold set where n >= threshold. We refer to each of these services as a realm.
At a glance, distributing secrets seems straightforward – secret sharing schemes have been widely used for almost half a century. However, it is not that simple. Running the naive approach outlined above across multiple realms, but replacing a client key with a client key share (a threshold shard of a key), does not actually help. If a single realm is compromised, the attacker can get the PIN out and use it to retrieve a threshold of the other key shares from the other realms.
Instead, a different approach is required that ensures neither a user’s PIN nor their full key ever leaves their device. This is a place where oblivious pseudorandom functions (OPRFs) can work their magic!
Oblivious, obviously
An OPRF is a cryptographic primitive that enables a realm to securely evaluate a function on a client’s input. This evaluation ensures the server learns nothing about the client’s input and the client learns nothing about the server’s private key beyond the result of the function.
Here’s how it works:
- The client generates a random blinding factor to obscure a user’s PIN, creating a “blinded” version of the PIN.
- This blinded PIN is sent to a realm, where a long-lived private key is used to compute a result without knowledge of the original PIN.
- Upon receiving the blinded result from the realm, the client removes the blinding factor, revealing the final result for the realm’s private key and the original PIN.
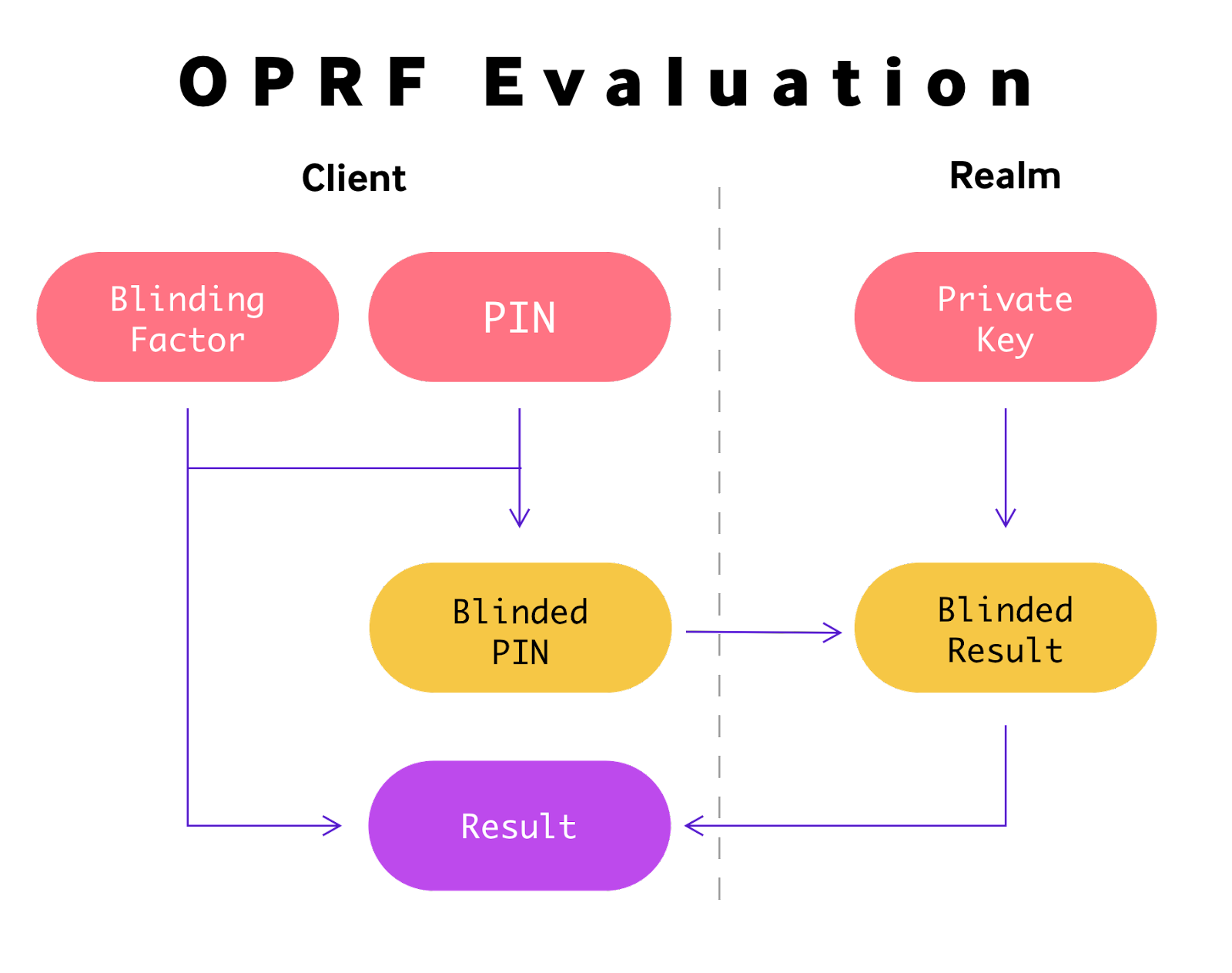
This final result can be used as a recoverable encryption key.
However, when you’re dealing with threshold realms, controlled by any number of operators, this model becomes impractical. Executing an OPRF evaluation for each realm (and calculating threshold independent results) incurs significant performance costs. Moreover, if one realm’s private key is compromised, it undermines trust in that realm for all users.
Enter Threshold OPRFs (T-OPRFs) – a variant on the traditional OPRF specifically designed to solve both of these problems by combining secret sharing with OPRFs. Each realm’s private key becomes a unique share of a random root private key created on the client during secret storage. This mathematical association of realm private keys enables us to optimize the operation to a single T-OPRF evaluation across the entire threshold of realms.
By creating shares of a single blinded input, and later reconstructing the blinded result shares received from each realm, we can reduce an entire threshold set to a single shared result. Additionally, since this approach requires the client to generate the associated keys for each realm, the client can also rotate those keys anytime it updates the stored secret.
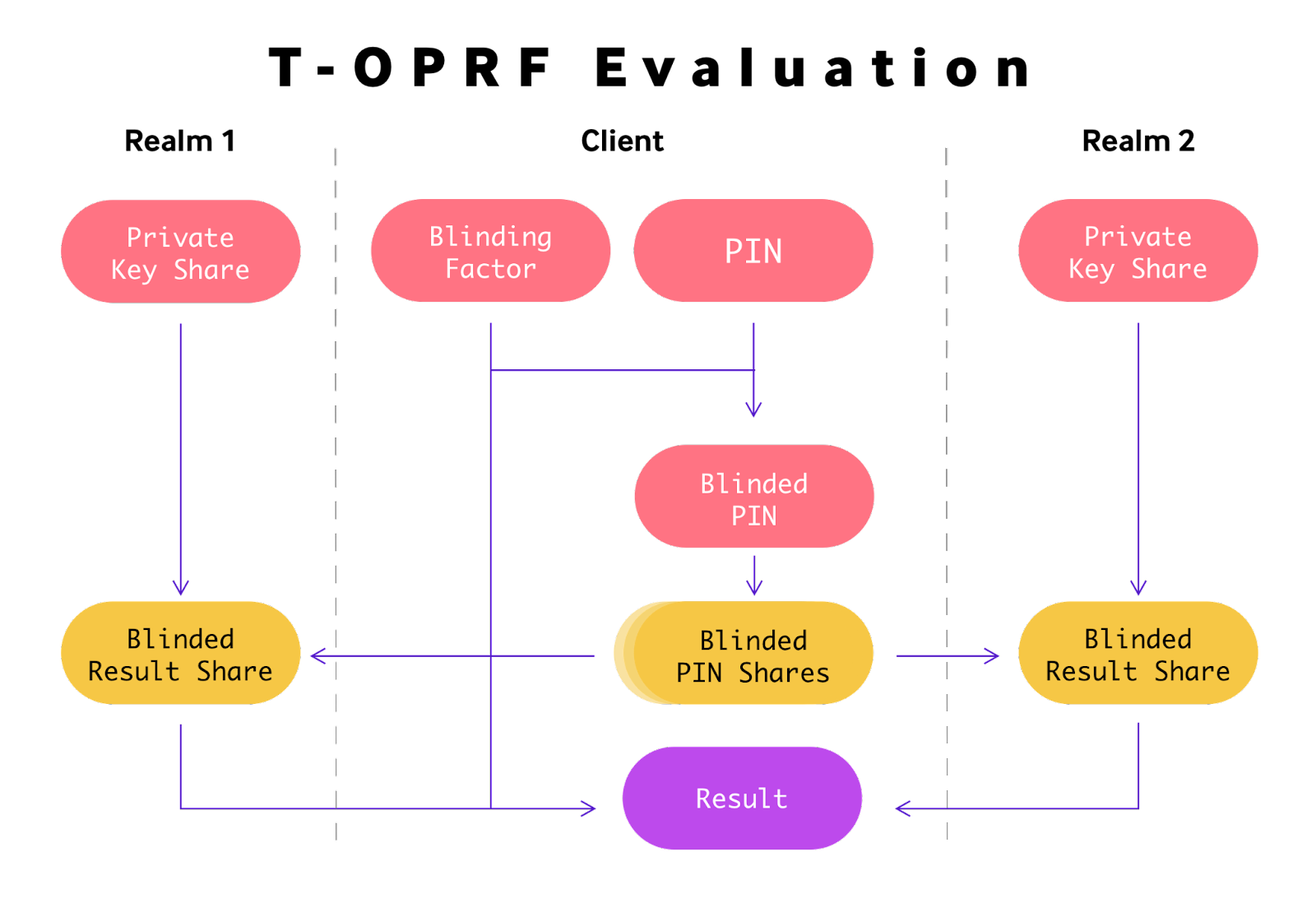
Since it requires threshold realms to acquire this new shared result, it can now be used in place of the user’s PIN in the original model when hashed with a realm’s address, greatly reducing the cost of the interaction.
- The client generates a root OPRF key, and creates n shares of it.
- The client computes an OPRF result locally using a PIN the user selects and the root key.
- The client hashes the result with each realm’s address, deriving threshold unlock tags.
- The client establishes a secure connection with the process running in threshold HSMs.
- The client creates shares of a key, and transmits a share to each HSM, along with the appropriate unlock tag and OPRF key share.
- The HSM securely stores the key share, unlock tag, OPRF key share, and a guess counter associated with that user.
- In the future, the client performs a T-OPRF evaluation with their PIN, and acquires the result.
- When the client derives and presents a correct unlock tag, the HSM returns the key share.
- The client reconstructs the key using the recovered key shares.
- The HSM uses the guess counter to limit the total number of possible attempts a client gets.
Ensuring integrity
When performing a T-OPRF over multiple realms, it becomes important to verify integrity of the shares so that one misbehaving realm cannot prevent recovery of a secret. To achieve this, we need a way to detect misbehaving realms and exclude them from recovery.
Since each realm maintains a unique private key share, the client can sign these shares before providing them to the realm at storage time, discarding the signing key. Then, during recovery, each realm can present its public verification key and signature at the start of the T-OPRF evaluation. This allows the client to quickly establish a threshold of realms that have matching verification keys, with valid signatures.
Unfortunately, this still leaves the door open for a threshold of realms colluding to provide valid signatures that were not generated by the client. To work around this issue, we need to additionally establish a consensus on a value which, if manipulated, would reveal itself to the client. Since the T-OPRF result is of sufficiently high entropy, we can split it into two parts: one continues to be utilized for unlocking secrets, while the other serves as a commitment stored with each realm. Now, we can establish consensus on a threshold of realms based on commitments and verification keys, and during the T-OPRF evaluation we can validate that the produced result contains a matching commitment. This prevents a colluding threshold of realms from substituting different OPRF key shares and signatures without knowing the PIN.
With these protections established, we’re in a much better place, but the door is still open for a realm to do everything right, while still returning a malicious OPRF result share to deny a user access to their secrets. We need a way to filter individual malicious realms out of a set, so the user can still proceed as long as threshold correct realms are present. The simplest path to solving this problem is allowing verification of the individual OPRF result shares, so we can reject a share and try a new realm without having to guess at random which realm has corrupted the set. Using zero-knowledge proofs, a realm can share its public key share with clients and provide cryptographic proof that its result share was generated correctly using the associated private key share.
There’s one last piece of information that realms have the chance to manipulate – the user’s secret share. Doing so could again potentially deny users access to their secrets, since the user would be unable to reconstruct them properly. We need a way to verify the secret has not been manipulated since storage. Since we can already verify the T-OPRF result, which we know at storage (and the realm never learns), we can solve this problem with a simple hash over the secret and T-OPRF result. We also want these hashes to be realm specific (so a malicious realm can’t copy them from another realm), so we mix in the realm’s share of the secret as well. During recovery, we can validate these values match, and remove any realms from the set that have tampered with the secret.
Trusting deliberately
The new paradigm we’ve established gives us the opportunity to look at ways we could supplement HSM realms in a threshold set with additional realms that are scalable and cost-effective.
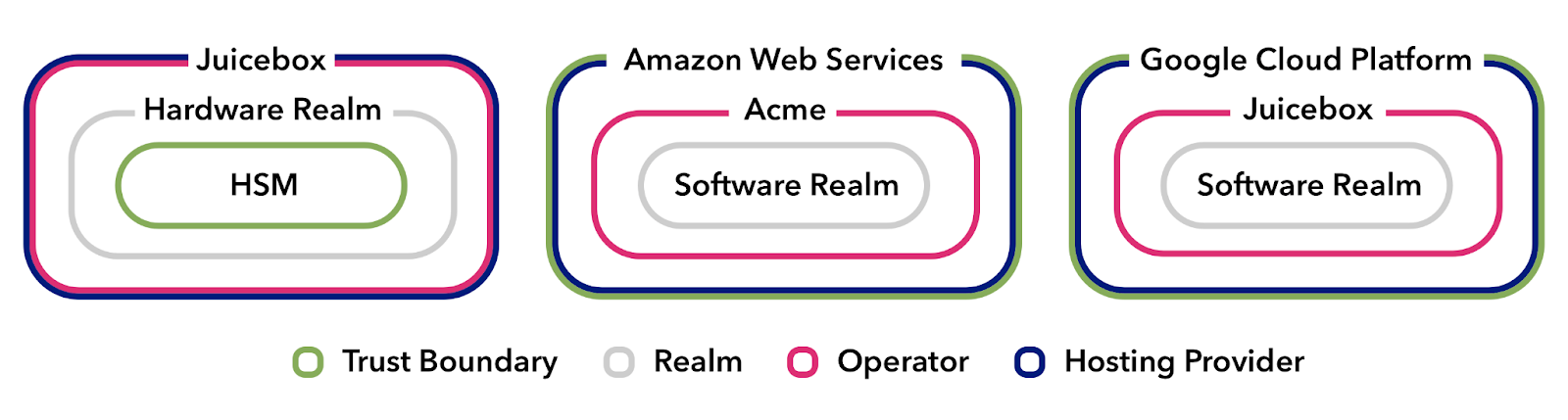
Juicebox supports two basic types of realm:
- A hardware realm is a type of realm backed by secure hardware — specifically a hardware security module (HSM), like we’ve been discussing. Hardware realms provide narrow trust boundaries as the HSM is designed such that only the hardware and the code it executes must be trusted. Not the operator.
- A software realm is a type of realm that runs on commodity hardware or in common cloud providers. When paired with hardware realms, they can be used to distribute trust organizationally without the overhead of operating secure hardware.
The Juicebox Protocol is specifically designed such that, as long as you are performing your operations on some hardware realms, with a threshold that requires their presence, it’s perfectly safe to include software realms in the operation to further distribute trust.
A simple configuration could consist of one hardware realm hosted by one organization and one software realm hosted by another, with a threshold of two. More complex configurations with multiple HSM vendors and cloud providers can be constructed to enable greater availability, reliability, and performance.
Hardware hurdles
In traditional setups using HSMs, data is stored within the limited persistent memory of these specialized devices. However, due to the constrained storage capacity of HSMs, storing a large dataset entirely within them is often impractical or even impossible, and any hardware failure can result in a loss of user data without the use of complicated replication schemes.
On the other hand, storing sensitive data in a traditional database would negate the benefits of HSMs entirely. Even if the records were stored in encrypted form, an HSM could not reliably distinguish an old version of a record from the latest version, thereby allowing an adversary with access to the hardware to roll back the state. Preventing roll-back attacks is crucial to ensuring realms cannot deny access to secrets, while maintaining strict limits on attacker guesses before secret material becomes inaccessible.
To work around these challenges, Juicebox uses a Merkle-Radix tree, allowing the service to scale to billions of secret records. These records are organized into trees, and the tree nodes can be safely stored in an external, untrusted storage system. The Merkle-Radix tree allows the HSMs to verify they are operating on the latest version of the record.
Juicebox’s implementation enables:
- Efficient Scalability: HSMs with limited capacity can efficiently handle requests on very large trees (billions of records) while ensuring data confidentiality, integrity, and freshness.
- Logarithmic Performance: Tree operations’ performance scales logarithmically with the number of records in the tree, a significant improvement over linear lookup key approaches.
- Dynamic Partitioning: The overall dataset can be dynamically partitioned across multiple trees, facilitating seamless scaling up or down with fast and inexpensive repartitioning.
- Parallelized Operations: Reads from each tree can be fully parallelized, even during ongoing writes, allowing HSMs to process continuous requests to mutate a tree without waiting for results to reach storage.
- Reduced Storage Cost: Tree nodes can be stored and cached freely on an untrusted, non-transactional storage system, reducing storage costs by enabling the use of highly scalable cloud storage solutions such as Bigtable.
Juicebox also employs an authenticated consensus protocol to recover from hardware failures, wherein HSMs validate freshness and authenticity on top of commodity hardware performing more traditional consensus. The ability to authenticate the entire Merkle-Radix tree with a single hash allows this consensus protocol to reach agreement on just a small amount of metadata as the tree evolves, making operations simpler and more efficient.
Auditing attempts
In the context of the naive storage system we initially discussed, one significant drawback is the lack of transparency regarding a user’s attempts to recover their secret material. Without this information, users are unable to gauge the security of their secret or take necessary precautions if their attempts are exhausted. Users have now come to expect a prompt notification of any attempts made against their stored secret, akin to receiving alerts for login attempts on their other accounts.
To address these concerns, each realm in our system logs recovery attempts – successful and unsuccessful – along with the remaining number of guesses. This data is made accessible through an API that clients can subscribe to, enabling functionalities such as push notifications to alert users when attempts are made against their accounts.
Wrapping up: try a sip of Juicebox
Juicebox’s source code is now available, and we encourage you to read our Juicebox Protocol and Merkle-Radix tree whitepapers for more detailed information. If you’re ready to try it out, a demo is available, configured for our sandbox realms.
Juicebox represents our earnest effort to tackle the challenges of end-to-end encryption key recovery with pragmatism and care. We’ve combined proven techniques like Threshold OPRFs and Merkle-Radix trees to create a solution that prioritizes security without sacrificing user experience. Our doors are open to feedback and collaboration as we continue to refine and enhance what we’ve created.
Juicebox was created by Alex Bochannek, Simon Fell, Moxie Marlinspike, Diego Ongaro, Daniela Perlein, and Nora Trapp. The project received valuable feedback from Trevor Perrin and was audited by NCC in June 2023.